
Hallo.
Danke für die wundervolle Software "FREETZ" !
Nach langem Suchen endlich gefunden.
Die richtigen und zielführenden Informationen mit denen es mir als Mod-Anfänger gelungen ist freetz1.01 auf meine Fritzbox 7050 zu installieren.
Für den Anfang ist dort nur ein Paket (cifsmount) eingesetzt. Als Gegenstelle (zum Mounten) habe ich eine LinkstationPro-250 (Festplattentausch->1000GB) mit Orginalfirmware.
Diese Zusammenstellung läuft jetzt ohne Probleme.
Zusätzlich ist das Tool "Fritz!Load" auf dem NAS funktionsfähig ausgelagert .
Bis jetzt konnte ich nur einen Fehler erkennen den ich hier melden möchte.
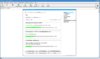
Auf der Freetz-Statusseite
Angezeigte Daten:
/var/tmp/usb (930.6G):
732.2 GB von 198.4 GB belegt
Was so ja nicht ganz stimmen kann.
Angehängt ein Print
Danke für die wundervolle Software "FREETZ" !
Nach langem Suchen endlich gefunden.
Die richtigen und zielführenden Informationen mit denen es mir als Mod-Anfänger gelungen ist freetz1.01 auf meine Fritzbox 7050 zu installieren.
Für den Anfang ist dort nur ein Paket (cifsmount) eingesetzt. Als Gegenstelle (zum Mounten) habe ich eine LinkstationPro-250 (Festplattentausch->1000GB) mit Orginalfirmware.
Diese Zusammenstellung läuft jetzt ohne Probleme.
Zusätzlich ist das Tool "Fritz!Load" auf dem NAS funktionsfähig ausgelagert .
Bis jetzt konnte ich nur einen Fehler erkennen den ich hier melden möchte.
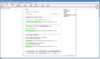
Auf der Freetz-Statusseite
Angezeigte Daten:
/var/tmp/usb (930.6G):
732.2 GB von 198.4 GB belegt
Was so ja nicht ganz stimmen kann.
Angehängt ein Print
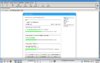
")